空指针问题 使用 Optional<T> 避免空指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Optional<User> optionalUser = Optional.ofNullable(user); User user1 = optionalUser.orElse(new User()); User user2 = optionalUser.orElseGet(() -> new User()); User user3 = optionalUser.orElseThrow(() -> new RuntimeException("异常了" )); optionalUser.ifPresent(u -> System.out.println(u.getName())); Integer nameLength = optionalUser.map(u -> u.getName()).map(name -> name.length()).orElse(0 ); System.out.println(nameLength);
使用 Objects 避免空指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 boolean equals = Objects.equals(null , new User());System.out.println(equals); boolean b1 = Objects.isNull(null );boolean b2 = Objects.nonNull(null );User[] ss1 = {new User("张三" )}; User[] ss2 = null ; boolean bb1 = Objects.deepEquals(ss1, ss2);System.out.println(bb1); ArrayList<User> users1 = new ArrayList<>(); users1.add(new User("张三" , new HashMap<String,Double>(){{this .put("语文" , 80.0 ); this .put("数学" ,90.0 );}})); users1.add(new User("李四" , new HashMap<String,Double>(){{this .put("语文" , 85.0 ); this .put("数学" ,95.0 );}})); ArrayList<User> users2 = new ArrayList<>(); users2.add(new User("张三" , new HashMap<String,Double>(){{this .put("语文" , 80.0 ); this .put("数学" ,90.0 );}})); users2.add(new User("李四" , new HashMap<String,Double>(){{this .put("语文" , 85.0 ); this .put("数学" ,95.0 );}})); boolean bb2 = Objects.deepEquals(users1, users2);System.out.println(bb2); System.out.println(Objects.toString(null ));
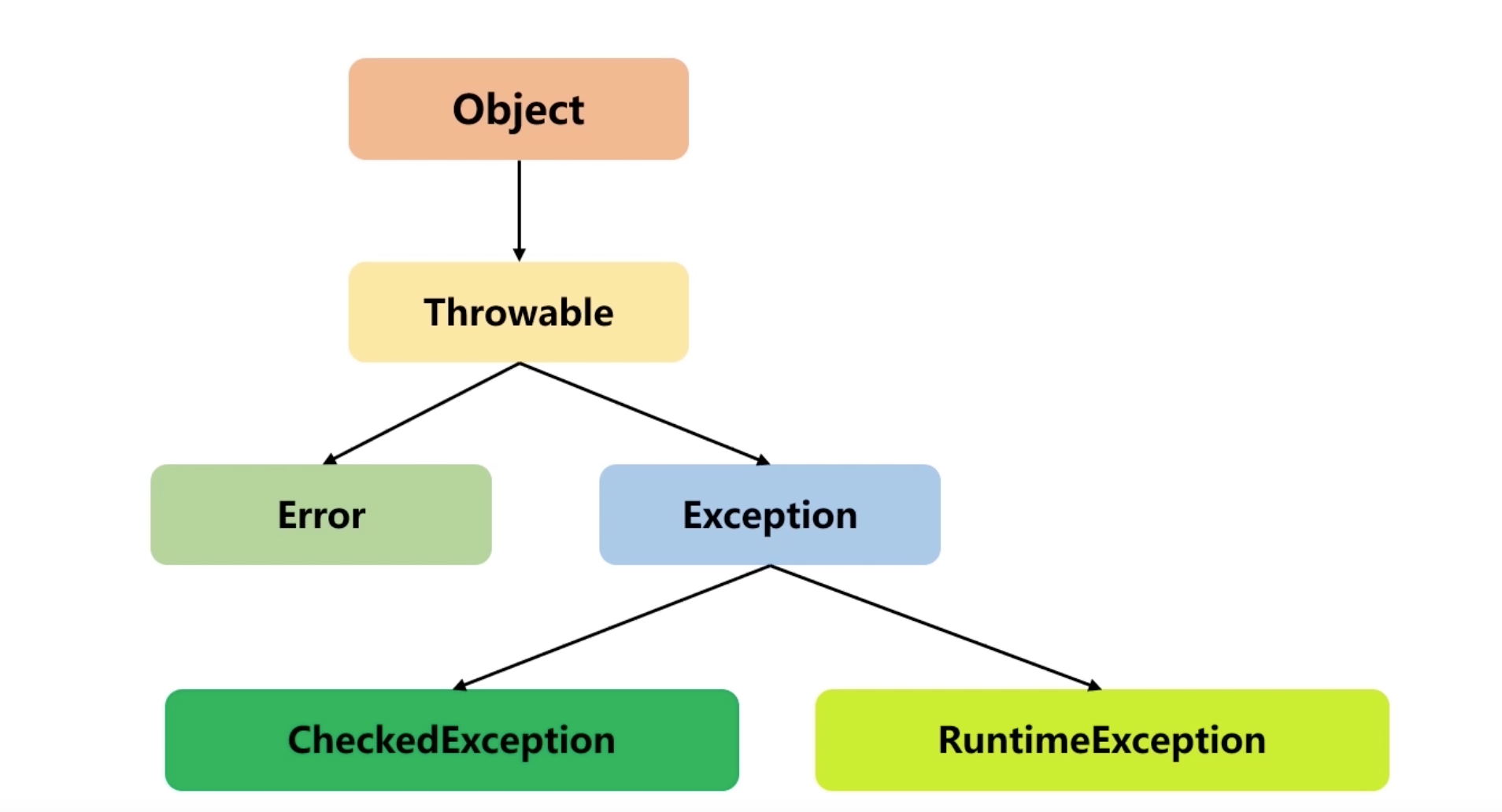
异常处理问题
并发修改异常 在遍历的过程中用错误的方式删除集合中的元素,会抛出并发修改异常:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 for (String s : list) { if (Objects.equals(s,"aa" )) { list.remove(s); } } Iterator<String> iter = list.iterator(); while (iter.hasNext()) { String s = iter.next(); if (Objects.equals(s, "aa" )) { iter.remove(); } } List<String> newList = list.stream().filter(v -> !Objects.equals(v,"aa" )).collect(Collectors.toList()); System.out.println(newList);
参数异常 例如枚举查找不到抛异常:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 static enum Status { SUCCESS(1 ,"成功" ), PROCESSING(0 ,"进行中" ), FAIL(-1 ,"失败" ); private static final Map<Integer, Status> indexMap = new HashMap<>(Status.values().length); static { Status[] statuses = Status.values(); for (Status status : statuses) { indexMap.put(status.getCode(), status); } } private int code; private String msg; Status(int code, String msg) { this .code = code; this .msg = msg; } public int getCode () return code; } public String getMsg () return msg; } public static Status findStatusByName (String name) try { return Status.valueOf(name); } catch (IllegalArgumentException e) { return null ; } } public static Status findStatusByCode (int code) return indexMap.get(code); } } public static void main (String[] args) Status status = Status.findStatusByCode(0 ); System.out.println(status); }
资源相关异常 关闭和释放资源操作:
try-with-resources语句是一种声明了一种或多种资源的try语句。资源是指在程序用完了之后必须要关闭的对象。try-with-resources语句保证了每个声明了的资源在语句结束的时候都会被关闭。任何实现了java.lang.AutoCloseable接口的对象,和实现了java.io.Closeable接口的对象,都可以当做资源使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 public static void testSingleResourceByTraditional () BufferedReader br = null ; try { br = new BufferedReader(new InputStreamReader(new FileInputStream("xxx/qqq.txt" ))); String line = null ; while ((line=br.readLine()) != null ) { System.out.println(line); } } catch (Exception e) { e.printStackTrace(); } finally { try { if (br != null ) { br.close(); } } catch (IOException e) { e.printStackTrace(); } } } public static void testMultiResourcesByTraditional () InputStream is = null ; OutputStream os = null ; try { is = new FileInputStream("xxx/qqq.txt" ); os = new FileOutputStream("xxx/qqq2.txt" ); byte [] bs = new byte [1024 ]; int len = 0 ; while ((len=is.read(bs)) != -1 ) { os.write(bs,0 , len); os.flush(); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if (os != null ) { try { os.close(); } catch (IOException e) { e.printStackTrace(); } } if (is != null ) { try { is.close(); } catch (IOException e) { e.printStackTrace(); } } } } public static void testSingleResource2 () try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("/Users/zhangqingli/Downloads/qqq.txt" )))) { String line = null ; while ((line=br.readLine()) != null ) { System.out.println(line); } } catch (IOException e) { e.printStackTrace(); } } public static void testMultiResource2 () try (InputStream is = new FileInputStream("/Users/zhangqingli/Downloads/qqq.txt" ); OutputStream os = new FileOutputStream("/Users/zhangqingli/Downloads/qqq3.txt" )) { byte [] bs = new byte [1024 ]; int len = 0 ; while ((len=is.read(bs)) != -1 ) { os.write(bs, 0 , len); os.flush(); } } catch (IOException e) { e.printStackTrace(); } }
精确计算问题 BigDecimal这个类的核心是 scale(精度),案例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public static void testBigDecimalScaleException () BigDecimal b1 = new BigDecimal("12.222" ); BigDecimal b2 = b1.setScale(2 , RoundingMode.HALF_UP); System.out.println(b2); } public static void testBigDecimalDivideException () BigDecimal b1 = new BigDecimal("10" ); BigDecimal b2 = new BigDecimal("3" ); BigDecimal result = b1.divide(b2,2 , RoundingMode.HALF_UP); System.out.println(result); } public static void testBigDecimalScaleEqualsProblem () BigDecimal b1 = new BigDecimal("0" ); BigDecimal b2 = new BigDecimal("0.0" ); System.out.println(b1.equals(b2)); System.out.println(b1.compareTo(b2) == 0 ); }
时间计算问题 SimpleDateFormat 使用上常见的坑:
它可以解析大于或等于它定义的时间精度,但是不能解析小于它定义的时间精度;
它是线程不安全的,在多线程环境下操作,会抛异常;
第一选择:定义SimpleDateFormat为局部变量
第二选择:使用ThreadLocal
第三选择:使用加锁机制 synchronized 或 ReentrantLock 等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public static void testSDF01 () throws ParseException SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd" ); Date d1 = sdf.parse("2020-09-09 10:00:00" ); Date d2 = sdf.parse("2020-09" ); } public static void testSDF02 () throws ParseException ThreadPoolExecutor pool = new ThreadPoolExecutor(10 , 100 , 1 , TimeUnit.MINUTES, new LinkedBlockingQueue<>(1000 )); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss" ); while (true ) { pool.execute(() -> { String ss = "2020-09-09 10:00:00" ; try { Date d = sdf.parse(ss); System.out.println(d); } catch (ParseException e) { e.printStackTrace(); } }); } }
hashcode 和 equals Set(底层实现也是map)和Map的键都不能重复,map的put方法是这样实现的:
首先hash(key)得到key的hashcode,hashmap根据获得的hashcode找到要插入的位置所在的链【注意,如果hashcode都不同,那么hashcode % map.length 得到的值也就可能不同,这时候没有hash碰撞的键自然也不会被调用equals方法,map中也就插入了两个相同的键】,在这个链里面放的都是hashcode相同的Entry键值对;
在找到这个链之后,会通过equals()方法判断是否已经存在要插入的键值对。如果已存在,则Map的键不变还是原来的对象,Map的新值覆盖原来的旧值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class User3 private String name; private int age; @Override public boolean equals (Object o) if (this == o) return true ; if (o == null || getClass() != o.getClass()) return false ; User3 user3 = (User3) o; return age == user3.age && Objects.equals(name, user3.name); } @Override public int hashCode () return Objects.hash(name, age); } } public static void main (String[] args) throws ParseException Set<User3> ss = new HashSet<>(); User3 u1 = new User3("张三" , 23 ); User3 u2 = new User3("张三" , 23 ); ss.add(u1); ss.add(u2); System.out.println(ss); HashMap<User3, Integer> m = new HashMap<>(); m.put(u1, 1 ); m.put(u2, 2 ); System.out.println(m); }
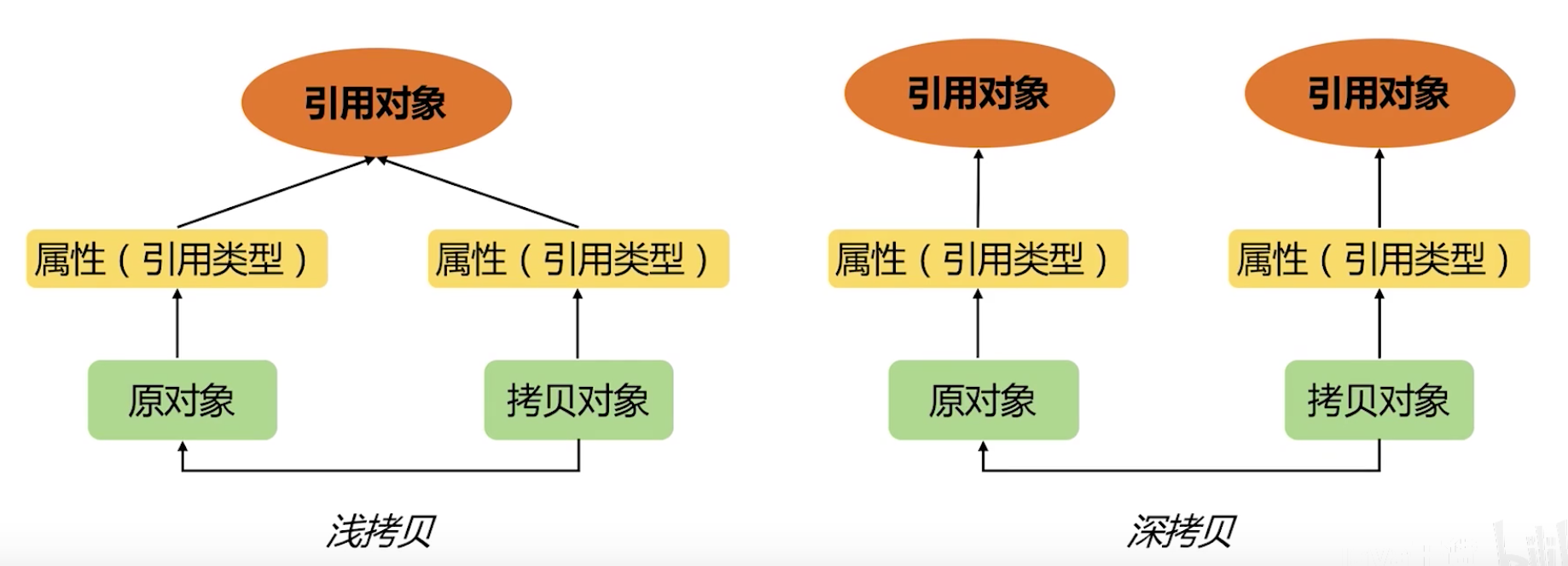
深拷贝和浅拷贝
Object提供的 protected native Object clone() 是浅拷贝
一个类实现拷贝,除了重写Object.clone方法,还需要实现 Cloneable 接口,否则会抛出 CloneNotSupportedException 异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Data @Data @AllArgsConstructor @NoArgsConstructor @ToString static class U1 implements Cloneable ,Serializable private Integer id; private String name; private Date birthday; @Override protected Object clone () try (ByteArrayOutputStream bos = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream(bos)) { oos.writeObject(this ); try (ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bos.toByteArray()))) { return (U1) ois.readObject(); } } catch (IOException | ClassNotFoundException e) { e.getStackTrace(); return null ; } } }
序列化和反序列化的坑 第一,子类实现序列化接口,父类没有实现,那么子类可以序列化吗?
答:只要父类中存在无参数的构造方法,那么子类是可以完成序列化和反序列化的。
第二,类中存在引用对象,那么这个类在什么情况下可以实现序列化呢?
答:只要类中的所有属性(包括基本属性和引用属性)都是可序列化的,那么这个类就是可序列化的。
第三,同一个对象多次序列化(之间有属性更新),会影响序列化吗?
答:会。同一个对象做多次序列化操作,结果也只被序列化一次(JVM根据序列化号判断),中间如果属性更新,是不会体现在序列化文件和反序列化对象中的。
使用lambok的坑 第一,尽量避免字段命名成例如 iPhone 这样的格式(jackson解析序列化,反序列化的过程中容易丢字段。注:fastjson测试OK);
第二,存在继承关系的子类,注意加上 EqualsAndHashCode 注解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Data @NoArgsConstructor @AllArgsConstructor public static class Computer private String name; private String version; } @Data @AllArgsConstructor @EqualsAndHashCode (callSuper = true ) public static class AppleComputer extends Computer private String color; private float price; public AppleComputer (String name, String version, String color, float price) super (name, version); this .color = color; this .price = price; } }
关于抽象类和接口的选择 抽象类是子类的通用特性,包含属性和行为;而接口则是定义行为,并不关系谁去实现;
抽象类是对类本质的抽象,表达的是is a的关系;接口是对行为的抽象,表达的是 like a 的关系;
关于抽象类和接口的选择,大的原则基本是:
如果对于聚焦的一类事物,它们的共性可以抽象为抽象类的形式;
对于特性的一些属性或方法,可以定义为接口;
例如下面的示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Data public abstract class BaseWorker private String name; private String position; protected abstract void clockIn (Date time) protected abstract void clockOut (Date time) } public interface Developer void develop () } public interface Tester void testing () } public interface Interest void playBall () void sing () } public class Worker extends BaseWorker implements Developer ,Interest }
关于synchronized关键字 synchronized是怎么实现的? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Test04 public static void main (String[] args) synchronized (Test04.class) { System.out.println("hello" ); } } } $ javap -l -p -c Test04.class ... public static void main (java.lang.String[]) Code: 0: ldc #2 // class Test04 2 : dup 3 : astore_1 4 : monitorenter 5: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream; 8: ldc #4 // String hello 10: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 13 : aload_1 14 : monitorexit 15 : goto 23 18 : astore_2 19 : aload_1 20 : monitorexit 21 : aload_2 22 : athrow 23 : return ...
从上述反编译结果就可以看出来,java中每一个对象或类对象都有一个对象监视器(monitor),当线程获取到对象的monitor之后才能继续往下执行(同一个时刻只能有一个线程持有该对象的monitor),否则就只能继续等待。
###JDK对synchronized做了哪些优化?
synchronized最大的特征就是,在同一个时刻,只能有一个线程能够获取到对象的监视器,从而进入到同步代码块或同步方法之中(互斥性)。那么这种方式是效率非常低下的(线程的切换),随着JDK的不断优化,对synchronized也做了大量的优化。Java1.8 ConcurrentHashMap 里面使用了大量的synchronized关键字对方法进行同步实现。那么JDK到底对synchronized做了哪些优化呢?简单的说,主要通过 锁升级,也就是一步一步将锁从很低的级别 到 很高的级别的过度,而这个过程中,线程的竞争程度也一步一步不断提高:
偏向锁:经过研究发现,大多数情况下,锁不仅不存在多线程的竞争,而且总是由同一个线程获得,为了让线程获得锁的代价更低,就引入了偏向锁。偏向锁使用了一种直到竞争出现才释放锁的机制,当其他线程尝试竞争偏向锁的时候,偏向锁线程才会释放锁。偏向锁的适用场景是只有一个线程进入临界区,而这个线程可能会始终持有这个对象的锁;
轻量级锁:一旦偏向锁的格局被打破,也就是有多个线程交替进入临界区,偏向锁就会 膨胀为 轻量级锁。轻量级锁的最大特点就是,等待轻量级锁的线程不会阻塞,它会一直自旋地等待,因此他也是一个自旋锁,尝试获取锁的线程在没有获得锁的时候,不会被挂起,而是执行一个循环(自旋),当若干个自旋还没有获取到锁,那么这个线程就会被挂起,直到获得锁去执行相应的逻辑指令;
重量级锁:最后当有很多个线程同时进入到临界区去竞争锁,这个时候,轻量级锁就会继续膨胀为重量级锁,重量级锁的最大特点是获取不到锁的线程会直接进入到阻塞状态,因为线程阻塞状态到运行状态存在线程上下文的切换,需要消耗大量的资源,因此被称为重量级锁。
多线程下更新变量值问题 下面以多线程下变量的累加为例做介绍,先看一下线程不安全的操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Test04 private static int count = 0 ; public static void main (String[] args) throws InterruptedException CountDownLatch cdl = new CountDownLatch(2 ); Thread t1 = new Thread(() -> { for (int i = 1 ; i <= 10000 ; i++) { count++; } cdl.countDown(); }); Thread t2 = new Thread(() -> { for (int i = 1 ; i <= 10000 ; i++) { count++; } cdl.countDown(); }); t1.start(); t2.start(); cdl.await(); System.out.println(count); } }
安全的更新变量的方式,可以采用 java.util.concurrent.atomic包下的原子类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Test04 private static AtomicInteger count = new AtomicInteger(0 ); public static void main (String[] args) throws InterruptedException CountDownLatch cdl = new CountDownLatch(2 ); Thread t1 = new Thread(() -> { for (int i = 1 ; i <= 10000 ; i++) { count.incrementAndGet(); } cdl.countDown(); }); Thread t2 = new Thread(() -> { for (int i = 1 ; i <= 10000 ; i++) { count.incrementAndGet(); } cdl.countDown(); }); t1.start(); t2.start(); cdl.await(); System.out.println(count.get()); } }
那么这些原子类的到底是怎么实现的呢?以 AtomicInteger.incrementAndGet 为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public final int incrementAndGet () return unsafe.getAndAddInt(this , valueOffset, 1 ) + 1 ; } public final int getAndAddInt (Object var1, long var2, int var4) int var5; do { var5 = this .getIntVolatile(var1, var2); } while (!this .compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; } public native int getIntVolatile (Object var1, long var2) public final native boolean compareAndSwapInt (Object var1, long var2, int var4, int var5)
可以看到其底层使用到了java的 CAS(Compare and Swap) 和 AQS机制(AbstractQueuedSynchronizer)。
CAS是一种无锁算法(乐观锁),相比于synchronized独占锁或称悲观锁有一定的效率提升。CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。比如,t1和t2线程都同时去访问同一变量56,所以他们会把主内存的值完全拷贝一份到自己的工作内存空间,所以t1和t2线程的预期值都为56。假设t1在与t2线程竞争中线程t1能去更新变量的值,而其他线程都失败。(失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次发起尝试)。t1线程去更新变量值改为57,然后写到内存中。此时对于t2来说,内存值变为了57,与预期值56不一致,就操作失败了(想改的值不再是原来的值)。通俗的解释是:CPU去更新一个值,但如果想改的值不再是原来的值,操作就失败,因为很明显,有其它操作先改变了这个值。AQS的核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并将共享资源设置为锁定状态,如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列,虚拟的双向队列即不存在队列实例,仅存在节点之间的关联关系。AQS是将每一条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node),来实现锁的分配。用大白话来说,AQS就是基于CLH队列,用volatile修饰共享变量state,线程通过CAS去改变状态符,成功则获取锁成功,失败则进入等待队列,等待被唤醒。
AQS是自旋锁:在等待唤醒的时候,经常会使用 自旋 while(!cas()) 的方式,不停地尝试获取锁,直到被其他线程获取成功。实现了AQS的锁有:自旋锁、互斥锁、读锁写锁、条件产量、信号量、栅栏等。