Alibaba DataX 源码编译和功能初探
DataX简介
设计理念
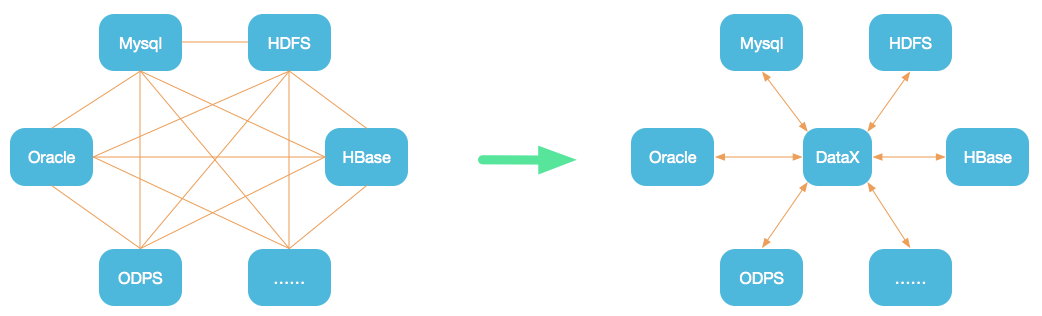
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。此前已经开源DataX1.0版本,此次介绍为阿里巴巴开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。
源码及文档: https://github.com/alibaba/DataX
DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断从Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
核心模块介绍:
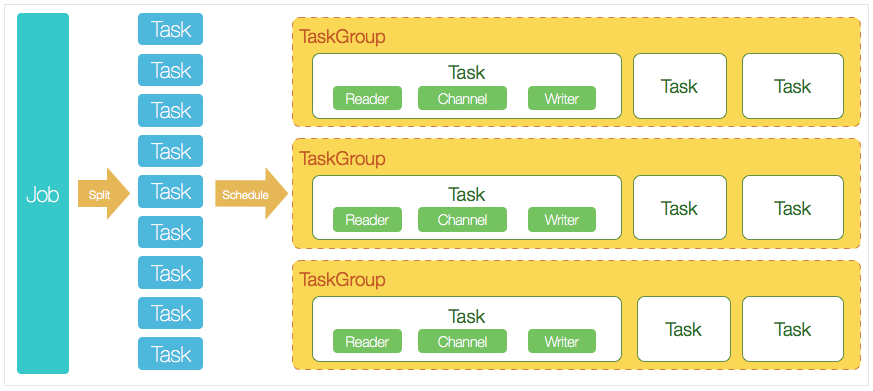
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup(20/5)。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
编译源码
1) 下载源码
1 | $ git clone git@github.com:alibaba/DataX.git |
2) 配置 maven setting.xml
1 | <mirrors> |
3) 打包
1 | $ cd {DataX_source_code_home} |
注:异常处理
异常一:
1 | [ERROR] Failed to execute goal on project odpsreader: Could not resolve dependencies for project com.alibaba.datax:odpsreader:jar:0.0.1-SNAPSHOT: Could not find artifact com.alibaba.external:bouncycastle.provider:jar:1.38-jdk15 in custom-mirror (https://maven.aliyun.com/repository/central) -> [Help 1] |
异常二:
1 | [ERROR] Failed to execute goal on project otsstreamreader: Could not resolve dependencies for project com.alibaba.datax:otsstreamreader:jar:0.0.1-SNAPSHOT: Could not find artifact com.aliyun.openservices:tablestore-streamclient:jar:1.0.0-SNAPSHOT -> [Help 1] |
其他异常:
1 | 多数是由maven仓库缺少jar包所致,可将maven镜像改为私服重试,私服配置如下: |
打包成功,日志显示如下:
1 | [INFO] BUILD SUCCESS |
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
1 | $ cd {DataX_source_code_home} |
dataX调优
DataX调优要分成几个部分(注:此处任务机指运行Datax任务所在的机器)。
- 网络本身的带宽等硬件因素造成的影响;
- DataX本身的参数;
- 从源端到任务机;
- 从任务机到目的端;
即当觉得DataX传输速度慢时,需要从上述四个方面着手开始排查。
网络带宽等硬件因素调优
此部分主要需要了解网络本身的情况,即从源端到目的端的带宽是多少,平时使用量和繁忙程度的情况,从而分析是否是本部分造成的速度缓慢。以下提供几个思路。
- 可使用从源端到目的端scp的方式观察速度;
- 结合监控观察任务运行时间段时,网络整体的繁忙情况,来判断是否应将任务避开网络高峰运行;
- 观察任务机的负载情况,尤其是网络和磁盘IO,观察其是否成为瓶颈,影响了速度;
DataX本身的参数调优
全局调优
1 | { |
局部调优
1 | "setting": { |
jvm调优
1 | python datax.py --jvm="-Xms3G -Xmx3G" ../job/test.json |
此处根据服务器配置进行调优,切记不可太大!否则直接Exception
以上为调优,应该是可以针对每个json文件都可以进行调优。
功能测试和性能测试
quick start https://github.com/alibaba/DataX/blob/master/userGuid.md
动态传参
如果需要导入数据的表太多而表的格式又相同,可以进行json文件的复用,举个简单的例子: python datax.py -p “-Dsdbname=test -Dstable=test” ../job/test.json
1 | "column": ["*"], |
上述例子可以在linux下与shell进行嵌套使用。
mysql -> hdfs
示例一:全量导
1 | # 1. 查看配置模板 |
示例二:增量导(表切分)
1 | { |
注意:外域机器通信需要用外网ip,未配置hostname访问会访问异常。
可以通过配置 hdfs-site.xml 进行解决:
1 | <property> |
或者通过配置java客户端:
1 | Configuration conf=new Configuration(); |
或者通过配置 datax 工作配置:
1 | "hadoopConfig": { |
示例三:增量导(sql查询)
mysql2hdfs-condition.json
1 | { |
hdfs -> mysql
1 | # 1. 查看配置模板 |
mongo -> hdfs
示例一:全量导
1 | { |
示例二:mongo增量导
1 | { |
hdfs -> mongo
1 | { |
datax 插件开发
略(待续)